
附录A.2. 模块及扩展库 《Python编辑基础及应用》
本书同名免费MOOC《Python编程基础及应用》在哔哩哔哩(B站)热播,作者带着你学。
附录A.2. 模块及扩展库
Python从诞生之日起,就提供扩展接口,鼓励参与者通过编写”库”来扩展其功能。这些第三方“库”既可以是Python编写的, 也可以是C语言编写的。Python作为一种胶水语言,可以很方便地与其它语言相互调用。
能使用C或者其它更高效的语言来扩展Python的事实极大地方便了程序员。对于那些对执行效率要求不高的部分,直接用Python写,以便事半功倍;对于那些对执行效率有苛刻要求的部分,比如自动驾驶系统里的图像识别:从画面中找出交通信号灯并识别红、绿和转向,就可以用C或者C++来高效实现。
为了展示将“开源”和“共享”进行到底的决心,Python书写的代码默认是没办法“保密”的。也就是说,你即使把Python“编译”成了pyc文件(一种由py文件经“编译”预处理后的文件格式),那些“有心”的软件使用者仍然可以不受约束地阅读和借鉴你的全部源代码。
作者目前只知道一种将Python代码“保密”的方法,那就是修改开源的Python解释器源代码,把其中的文件存储的部分改成“加密”的。这种做法在“开源”社区可能很不受欢迎。
A.2.1 Python扩展库
丰富的包/模块以及源源不断由开源社区的"雷锋"们制造的第三方扩展包/模块是Python广受欢迎的重要原因。现在作者试图用Python解决任何工程问题,决不是简单的"埋头苦干",而是先搜索一下有没有现成的库可以利用。这些库有的包括在标准的Python安装里,称为“标准库”,有的需要单独安装。无论是“标准的”还是“第三方的”库,都是对Python功能的扩展,统称扩展库。下表介绍了一些”重要”的Python扩展库。
| 名称 | 简介 |
|---|---|
| PyQt4/PyQt5 | Qt是一个历史悠久,广受赞誉的跨平台C++开发库及IDE。它可以非常容易地编写图形界面应用程序,甚至手机App。目前在用的有Qt4和Qt5两个版本。而PyQt4/PyQt5是对Qt的Python封装,通过它们,你可以使用Python来操作Qt的”C++身体”。本书的后半部分会有单独介绍使用PyQt制作图形界面应用程序的章节。 |
| scipy | SciPy是个开源的免费Python库,其包含诸多模块以支持各种形式的科学和工程计算:优化、线性代数、积分、插值、FFT-快速傅里叶变换,信号和图像处理等。作者曾使用scipy.stats模块来进行某些健康人群生理指标的正态分布计算和估计。项目网址:www.scipy.org。 |
| pyserial | 串口(包括虚拟串口)的Python语言接口。作者曾通过它让计算机与某些工业设备进行通信。 |
| numpy | 用C语言编写的多维数组模块,能快速地创建和计算多维数组。它是scipy, matplotlib, opencv-python等模块的基础。 |
| opencv-python | 提供OpenCV库的Python接口。OpenCV是一个主要针对实时计算机视觉的编程功能库,最初由英特尔开发。 该库是跨平台的,可以在开源BSD许可下使用。作者曾借助于OpenCV库来识别医疗监视图影像中的人眼瞳孔的位置和注视方向,以评估医疗对象在医学检查过程中的关注度。 |
| cython | 提供一种使用C和Python的混合语言编写Python扩展库的方法。 |
| configparser | 提供与设备的modbus通信协议支持。modbus是现代工业设备间常用的通信协议之一。读者家里的热水器或者中央空调如果有远程控制终端的话,这些远程控制终端与主机之间,很可能就是modbus协议,而在通信的底层,又很可能是485或者RS-232串口协议。作者曾用该模块让工业机器人与某种外部运动控制器进行交互。 |
| tkinter | Python标准安装中自带的GUI工具包。帮助用户创建图形用户界面(Graphics User Interface)的应用程序。 |
| ReportLab | 一种用于绘图和生成PDF文档的开源软件包。 |
| pygame | 一个跨平台的Python游戏开发包。年幼的初学者或者童心未泯的大同学可以尝试用pygame开发一个街机游戏。这个包里还自带一些图像和音频库供学习者使用。 |
| matplotlib | matplotlib是一个可绘制印刷级质量图表的跨平台2D/3D库,可以方便地从数据生成并绘制折线图、直方图、饼图和其它各种专业图表。 |
| django,flask,pyramid | 这三者都是基于Python的Web框架,简单地理解就是用于构建Web网站的。如果读者期望开发小型的Web应用,使用这些框架是合适的。但作者不得不说,当前最主流的Web前端框架是基于JavaScript的Bootstrap、Vue、React之类;而最主流的Web后端框架则是基于Java的SpringFramework。如果读者想学习构建专业的大型Web应用,至少目前,还是应该考虑由JavaScript、Java、HTML5、CSS3等构成的宠大的阵营。 |
| pandas | Python Data Analysis Library - pandas最初是作为金融数据分析工具被开发出来的,它基于numpy。现在已经成为使用Python进行数据分析的主流工具。 |
Python扩展库的使用者如果试图将软件商业化, 则需要注意相关扩展库的授权协议,常见的协议有:BSD, Apache,GPL, LGPL, MIT等等。这些协议描述了扩展库的拥有者对你的授权:是否可以商业化? 是否必须开源?简单地说,BSD几乎不对使用者进行任何限制,而GPL则要求任何基于GPL开源代码的衍生软件也必须开源。遵重原作者的权利,是每个人的义务。在可能的情况下,尽可能开源和共享,是作者对读者的期待。
A.2.2 了解模块
使用一个模块(module)前必须先了解这个模块。除了网上检索,阅读其官网上提供的文档外,Python解释器还提供了一些简便的方法。说明一下,本节中的代码在Python控制台中直接执行或更为简便。
A.2.2.1 dir
1 | #dir.py |
执行结果
1 | <class 'module'> |
上述执行结果中的省略号是作者打的,目的是节约用纸,保卫地球。
import os之后,os对于解释器而言,也仅是一个名字而已, 这个名字关联的对象是模块(module)类型。dir(os)返回一个列表,列出了os模块内的全部属性,包括函数、类、变量等等。读者可以看到,上述代码的第三行使用了列表推导来过滤掉那些预期仅用于模块内部的以下划线开头的名字。
一个有经验,或者有英文基础的编程者很容易从dir(os)返回的信息中找到有价值的函数和功能。比如,chdir()函数显然是change directory的缩写,其用途是修改程序的当前工作路径。
A.2.2.2 __all__属性
1 | #all.py |
执行结果
1 | ['altsep', 'curdir', 'pardir', 'sep', 'pathsep', 'linesep', 'defpath', 'name', 'path', ..., 'abort', 'access', 'chdir', 'chmod', 'close', 'closerange', 'cpu_count', 'device_encoding', 'dup', 'dup2', 'environ', 'error', 'execv', 'execve', 'fspath', 'fstat', 'fsync', 'ftruncate', 'get_handle_inheritable', 'get_inheritable', 'get_terminal_size', 'getcwd', 'getcwdb', 'getlogin', 'getpid', 'getppid', 'isatty', 'kill', 'link', 'listdir', ... , 'mkdir', 'open', 'pipe', 'putenv', 'read', 'readlink', 'remove', 'rename', 'replace', 'rmdir', 'scandir', ..., 'system', 'terminal_size', 'times', 'times_result', 'truncate', 'umask', 'uname_result', 'unlink', 'urandom', 'utime', 'waitpid', 'write', 'makedirs', 'removedirs', 'renames', 'walk', 'execl', 'execle', 'execlp', 'execlpe', 'execvp', 'execvpe', 'getenv', ..., 'spawnle'] |
有经验的程序员或者仅凭上述输出就可以大致了解os模块的用途。比如, mkdir()函数有点象makedir的缩写,是的,它的功能就是创建一个目录;那getcwd呢? get current working directory,返回当前工作路径;kill呢?杀谁?它可以杀死一个操作系统进程。初学者如猜不出上述名称的意义,是正常表现,不要沮丧。
这个属性叫做__all__,但名不符实。这个属性是一个列表,包含了模块开发者认为的预期可以被使用者使用的部分名字。言下之意,那些没有包括在该列表内的名字,则属于模块"隐藏的实现"(hidden implementation),不欢迎使用者"强行"访问。
如果我们执行代码from os import *,则会将os.__all__下的名字引入当前程序的全局作用域当中。如果我们自己写模块,那么为模块恰当地定义__all__属性是必要的:仅把那些用于接口的名字包括在该属性列表中。
作者打开了os模块的源文件:os.py,在其中,找到了下述赤裸裸的代码:__all__属性就是这么直接了当地被初始化然后又在后面的代码中逐渐增加名字。这段代码中第一行的注释提醒阅读者:不要误以为__all__只包含这些初始的名字,后面还会逐步增加。
1 | # Note: more names are added to __all__ later. |
A.2.2.3 help()函数
1 | #help.py |
执行结果
1 | ------------help(chdir)--------------- |
上述代码中,我们通过help()函数查看了chdir函数的使用帮助。上述信息指出,上述chdir()函数接受一个path参数,其作用是将系统的当前工作路径切换至指定路径。这是关于这个函数最可靠,最直接的文档。
通过print(chdir.__doc__)也可以获得类似信息,只不过内容更少一点。
A.2.2.4 查看源代码
1 | #file.py |
执行结果
1 | C:\Users\CH\AppData\Local\Programs\Python\Python37\lib\os.py |
透过模块的__file__属性,我们可以查询到模块的源码文件的路径。可以使用Visual Studio Code打开该源码文件以期了解其内部实现。注意,千万不要修改标准库中的源码文件。
A.2.2.5 Python文档
除了上述途径之外,如果读者的英文还过得去,Python解释器的原始文档是获取简洁可靠帮助信息的最佳途径。在安装了Python解释器之后,Windows的开始菜单中可以找到Python 3.x Manuals。
作为选项,读者也可以直接访问python.org,当前网址是:https://docs.python.org/3/。
这些信息源远比使用搜索引擎搜出来的转了N次的信息更为可靠。顺便说一句,如果读者想成为专业的程序员,英文如果不好,多半是个硬伤。
A.2.3 创建模块
一般地,模块就是程序员编写的构成应用程序的多个Python文件中的某一个文件,它负责完成程序当中的某个特定任务。为了说清问题,作者期望构建一个名为Stat的模块。这个模块虽然简单,但它来自于作者真实的软件项目实践。
| Stat模块需求简述 |
|---|
| - 在自动化蔬菜种植工厂中负责叶菜(典型如韭菜)收割的机器人需要对工作量进行统计,该功能被抽象成Stat模块。该模块需要记录和管理两个数据:1. 从机器人交付之日起,总共收割的叶菜周转盘数;2. 本次开机后,机器人总共收割的叶菜周转盘处。 - 模块应负责这些数据的自动存取,机器人启动时自动从文件读取计数,数据能在机器人的多次启闭间得到保持。 |
作者创建了一个名为”Stat.py”的文件,这个文件就是一个Python模块,模块名即文件名Stat:
1 | #Stat.py |
这个简单的模块做了如下几件事情。首先,它定义了一个名为Stat的新类。按照万物皆对象的理论,这个模块本身是一个对象,Stat类是这个对象作用域下的子对象。一个Stat对象包括两个数据成员,iCounter用于记录本次启动后收割的叶菜盘数,iTotal则记录机器人历史上总共收割的叶菜盘数。我们注意到,Stat类通过configparser将相关数据存取至结构化ini文件中,其__load()、__save()方法分别负责数据读取和存储。这两个方法通过函数名前加下划线的形式被隐藏起来了,出于接口简便性的考虑,模块的作者并不希望使用者直接使用这两个方法。Stat类的add()方法将相关计数加1然后保存至文件,这是该类唯一向外提供的接口。接下来,通过print()函数,模块打印了一行表示自身被导入的消息。最后,模块创建了一个名为stat的Stat类型对象。
代码中的os.path.expanduser(‘~’)用于返于当前操作系统登录用户的Home目录,读者可以在代码中加一行,print(sFileName),看看该路径在哪里。注意,os.sep返回当前操作系统所使用的路径分隔符,在Windows系统下,该分隔符为”\“,而在Linux下,则为”/“。
做个简单的总结:Stat模块自身是一个对象,有单独的作用域,其下有两个名字,Stat和stat,Stat是一个类,stat则是Stat类型的对象。
A.2.4 使用模块
模块是用来做定义的,也就是向系统介绍新的类、新的函数。不要试图在模块中过多地直接运行功能性代码。模块因被使用而体现其价值。作者创建了一个名为Main.py的程序来模拟上节Stat模块的使用者。当前,Main.py和Stat.py被放在同一个目录内。
1 | #Main.py |
执行结果
1 | 'Stat' module imported. |
首先,代码通过from Stat import stat以及import Stat两种方式共3次导入Stat模块。根据“华丽分界线”所表达的成果,我们注意到只有第一次导入时Stat模块被真正运行并打印了”Stat module imported.”的信息。模块只在第一次被导入时被运行是一个重要的特性:首先当然节省时间;其次,当A模块引用B模块,B模块引用A模块的复杂状态发生时,该特性可以避免无穷的导入循环。
import Stat导入了模块Stat,可以把该模块视为一个有独立作用域的对象。此时,如果你希望使用该模块内的Stat类,完整的名称就应该是Stat.Stat。对该名字的打印结果证实,它就是一个类对象,类型为<class ‘Stat.Stat’>。而模块内的类型为Stat的变量stat,其完整名称应为Stat.stat。
from Stat import stat是另外一种语法,它完成两件事:导入运行Stat模块; 将Stat模块内的名字stat”介绍”至当前作用域。此时,Stat.stat与stat两个名字处于不同作用域,但显然,它们绑定在同一个对象上。执行结果中显示的id值证明了这一点。
接下来,代码通过random模块生成一个介于1和16之间的随机数并执行stat.add()模拟机械人的收割工作。在经过多次运行后,作者得到13/76的计数值,证明该模块内的计数在不同次运行之间得到了良好保存。
作者还想提一下Stat模块的小而美的设计,它提供简单的接口 - add()函数,并把“复杂”的实现 - 数据存取部分隐藏起来。这样,将来模块的作者就有机会将计数的存储位置由文件改成数据库,而模块的使用者几乎不用做任何适应性修改。
A.2.5 模块测试
在模块Stat中,我们注意到一行代码:
1 | print(__name__,"module imported.") |
当Stat模块被Main.py导入并导致其运行时,__name__的值为’Stat’。读者可以尝试直接运行Stat.py,此时解释器内置变量__name__的值为’__main__‘。
所以,如果模块的设计者试图给模块添加一些测试代码并希望当且仅当该模块文件被单独运行时才执行测试代码,可以这么写:
1 | if __name__ == "__main__": |
A.2.6 包
在一个应用程序中,Python程序文件可能多达几十甚至几千个。我们不可能把所有的文件都放在同一目录下,这样太乱了。读者可以简单地认为包(package)就是包含模块文件和其它包的文件目录。
在Visual Studio Code中,作者在项目目录下新建了一个名为Utils的子目录 - folder,然后把之前的Stat.py移至该子目录下。按照Python规范的要求,还在子目录下创建了一个名为__init__.py的文件。这个__init__.py文件的存在,是这个目录可以当成包使用的必要条件。简言之,我们现在有了这样一个目录结构,Main.py所在目录有一个名为Utils的子目录,子目录下有文件__init__.py以及Stat.py。
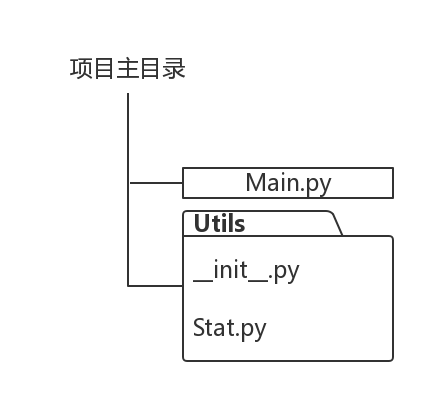
现在,Stat模块不再与Main.py处于同一目录,而是处于下方包Utils之内。现在的Main.py应做相应修改,以便使用Stat模块。
1 | #Main2.py |
执行结果
1 | Utils.Stat module imported. |
可以看到,对于模块Stat而言,其__name__已变成了”Utils.Stat”。当然,我们还有更多在Main.py内导入模块的方法。只不过导入方法不同,名字的作用域会不同,下表以模块内的stat变量为例,说明这种差异。
| 不同模块导入方法 | stat名字全称 |
|---|---|
| - from Utils import Stat | Stat.stat |
| - import Utils.Stat | Utils.Stat.stat |
作为一个对象,包Utils也可以有代码和属性,而__init__.py则可用于此目的。作者修改了Utils下的__init__.py:
1 | #Utils/__init__.py |
如下代码:
1 | #useutils.py |
将得到下述执行结果
1 | Utils package imported. |
A.2.7 应用程序的目录结构
如同列表可以包含列表一样,包也可以包含子包。所以,一个模块众多的应用程序,通常长成下述模样:在项目的主目录下,有一个程序的总启动文件,比如Main.py。然后在主目录下,有众多的子目录-包,以及众多的更下层子目录。每一个子目录内的模块都完成一个特定的任务,有的负责执行关键任务,有的完成系统配置,有的负责报表生成和打印…… 众多模块分工合作,形成一个完整的应用程序。
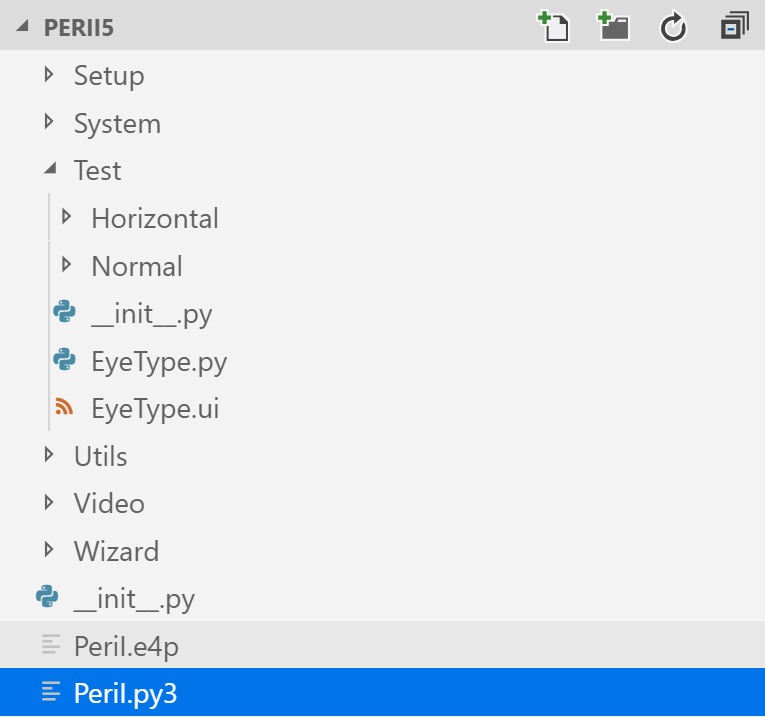
下图展示了作者编写的一个应用程序的目录结构,这是一个用于眼科医疗仪器的用Python编写的软件。其中,PeriI.py3是项目的主启动文件。读者可以看到,在PeriI.py3所在项目主目录下,有众多的下层目录及下下层目录。
A.2.8 让程序找到你的模块
如果是项目私用的模块,那么按照上一节所描述的方法组织项目的目录结构就很好。如果希望把模块/包开放给其它应用程序或者程序员所使用,我们就需要了解Python解释器是如何定位包/模块的。也就是说,当解释器遇到一个import语句要求导入一个包/模块,解释器去哪里找到这个包/模块呢?
1 | #libpath.py |
执行结果
1 | ['d:\\pylearn\\C14_Modules', |
当试图导入包/模块时,解释器会沿sys.path指引的路径逐一查找。你可以通过sys.path.append()函数将你自定义的模块路径加入到sys.path当中。也可以把相应包和模块拷贝到site-packages目录(推荐放这里)。
我们还注意到,上述打印结果的第一行就是被运行的Python主文件的所在目录。这说明,当前工作路径是优先被搜索的。
说明一下,pprint即是一个打印模块,它可以相对漂亮地处理文本输出。
A.2.9 标准库
Python的标准安装里自动附带了很多的标准库,使得你“几乎”能够立即着手真正的工作,这就是Frank Stajano提出的”Batteries Included” - 电池已配,有人形象称之为“开箱即用”。
| 名称 | 简介 |
|---|---|
| sys | - 允许程序员访问与Python解释器紧密相关的变量和函数。比如: argv - 命令行参数; path - 模块搜索路径列表; platform - 平台标识,表示当前解释器在何种操作系统下运行,比 win32, linux之类; stdin,stdout,stderr - 标准输入,输出,错误流; exit([arg]) - 函数,退出应用程序。 |
| os | - 允许程序员使用操作系统服务。os是operating system的简写,就是操作系统的意思。通过该模块,程序员可以创建、删除文件夹,执行外部程序,开启新的进程,获取设置系统环境变量,获取当前工作路径等等。读者可以尝试打印一下os.environ,它即是一个包含了全部环境变量的字典。 |
| heapq | - 堆是一种著名的数据结构,也称为优先队列。借助于堆/heap,可以在log(n)的计算复杂性下从n个元素中取得最大值或者最小值。请参考数据结构教材中的“堆排序”一节。heapq模块支持Python下的堆操作。 |
| collections | - 包含一些容器类数据类型,比如双端队列(deque)。 |
| time,datetime | - 支持日期和时间获取与操作。 |
| timeit | - 可帮助计算代码段的执行时间。 |
| random | - 伪随机数生成模块: random() - 返回一个0-1的随机实数; choice(seq) - 从序列seq中随机返回一个元素; shuffle(seq[,random]) - 把序列打乱; sample(seq,n) - 从序列seq中随机选择n个值不同的元素。 |
| shelve | - 提供数据的文件存取支持,作用类似于json,但存储格式不同。 |
| re | - 正则表达式 - regular expression模块。正则表达式是处理复杂形式字符串匹配/替换等操作的强大工具,可以完成诸如从邮件文本中提取出发件人,从隋唐演义中找到所有的李姓人名并统计出场次数,从网页文本中提取各种格式电话号码这样复杂的任务。它很强大,也很复杂。当读者遇到需要对文本进行复杂操作的任务时,请别忘了re模块。 |
| logging | - 提供一系列应用程序日志的记录工具。看起来,作者好像也犯了重新发明轮子的错误: 读者可以查询标准库文档,看看是否可以优化第12章的出错日志一节的程序。 |
A.2.10 扩展库的安装方法
https://codelearn.club/2019/06/pipinstall/
本书同名免费MOOC《Python编程基础及应用》在哔哩哔哩(B站)热播,点击加入,作者带着你学。
练习
14-1 请在你的计算机上使用pip install安装numpy, scipy,matplotlib, PyQt5, opencv-python等扩展库。安装前后请注意Python安装路径下site-packages 子目录里的变化。
14-2 使用dir(), help()等函数了解numpy模块的功能。
14-3 将13章随书代码中的fibiter.py修改成一个模块文件,即删去除Fibonacci类定义之外的执行代码部分。然后,在同一目录下编写一个名为fibdemo.py的代码文件,在其中导入fibiter.py中的Fibonacci类,并使用该类迭代打印斐波那契数列的前20项。
