
在随书源代码的CH10/Family子目录下,文件FamilyFinanceData.csv存储了经过整理的涉及3万多户中国家庭,10万个家庭成员的家庭收入及财产数据。这是一个逗号分隔值文件,使用Excel或者WPS软件打开,其内容结构如图10-P2所示。
数据来源:西南财经大学中国家庭金融调查与研究中心,中国家庭金融调查数据库,2019年。受限于版权,随书代码中提供给读者的数据并非原始数据,但保持了与原始数据类似的统计学特征。
数据及源代码下载
http://codelearn.club/download/Family.zip
版权声明
本文节选自《Python编程基础及应用》第2版,高等教育出版社,作者:陈波,刘慧君
本文可以在互联网上自由转载,但必须:注明出处(作者:海洋饼干叔叔)并包含指向本页面的链接。本文不可以以纸质出版为目的进行改编、摘抄。
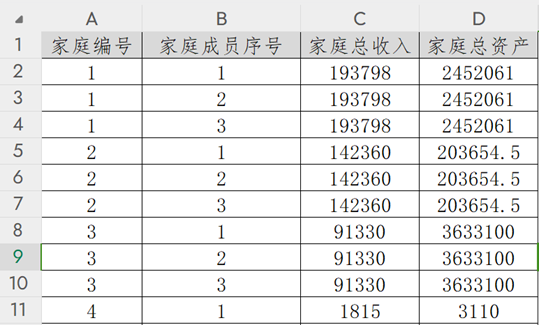
如图10-P2所见,文件中的每一行对应一位家庭成员。以2号家庭为例,该家庭有序号1至3共3位家庭成员,家庭年度总收入为142360元,家庭总资产为203654.5元。
计算家庭人数
相较于家庭年度总收入和家庭总资产,人均年度收入和家庭人均资产更能真实地反应居民的收入和财产状况。为了得到平均数据,我们先统计各家庭人数。
IDLE Shell
1 | >>>import pandas as pd |
首先,我们使用pd.read_csv()函数将文件读入为DataFrame。文件的路径请读者按自己计算机上的实际路径修改。df.head(10)的执行结果显示,文件被成功读入,结构与图10-P2所示一致。
IDLE Shell
1 | >>>s = df.groupby("家庭编号").size() #按家庭编号分组统计人数 |
接下来,使用df.groupby(“家庭编号”).size()函数对DataFrame按家庭编号进行分组,并统计每组人数。执行结果显示,统计结果s是一个Series,其索引为家庭编号。其中,1号家庭有3人,4号家庭有1人。
IDLE Shell
1 | >>>s = pd.DataFrame({"家庭编号":s.index, "家庭人数":s.values}) |
以结果Series的索引s.index为“家庭编号”列,值序列s.values为“家庭人数”列,创建DataFrame。
IDLE Shell
1 | >>>df.head(2) |
如上述结果所示,df和s都有一个名为“家庭编号”的列,两个DataFrame中的数据可按家庭编号对应。因此,我们使用pd.merge()函数将两个DataFrame按“家庭编号”合并。
IDLE Shell
1 | >>>df = pd.merge(df,s,on="家庭编号") |
合并结果显示,除原有列外,DataFrame新增家庭人数列。
计算人均年收入及人均资产
IDLE Shell
1 | >>>df["人均年收入"] = df["家庭总收入"] / df["家庭人数"] |
如上所示,将家庭总收入列与家庭人数列相除,即得人均年收入列。将家庭总资产列除以家庭人数列,即得人均资产列。
IDLE Shell
1 | >>>df.to_csv("d:/PyLearn2/CH10/Family/Stat.csv",index=False) |
为方便后续使用,使用df.to_csv()函数将当前统计结果存入Stat.csv文件中。读者执行上述代码时,需要按自己计算机上的路径进行修改。
居民的人均年收入分析
IDLE Shell
1 | >>>import pandas as pd |
首先,从统计结果文件Stat.csv读入DataFrame,然后取得“人均年收入”列。执行结果显示,avg是一个Series,其中存储了106754位居民的人均年收入。
IDLE Shell
1 | >>>avg.mean() #人均年收入均值 |
Series提供一系列的统计函数,其中,mean()计算均值,median()计算中位数。执行结果显示,居民人均年收入约为两万七千元,中位数约为一万六千元。
IDLE Shell
1 | >>>avg.std() #人均年收入标准差 |
如上所示,Series的std()、max()、min()成员函数分别计算Series的标准差,最大和最小值。金融调查数据中,有部分家庭的年度总收入为负值,这多半是由诸如股市亏损之类的经营性亏损导致的。
IDLE Shell
1 | >>>import matplotlib.pyplot as plt #导入matplotlib |
以matplotlib为基础,pandas也支持统计绘图。上述代码中,avg.hist(bins=10000)将人均年收入数据分成10000个区间,统计落入每个收入区间的人数,并绘制直方图。为便于观察,我们将x轴显示范围设为-1万至20万,绘图结果见图10-P3。
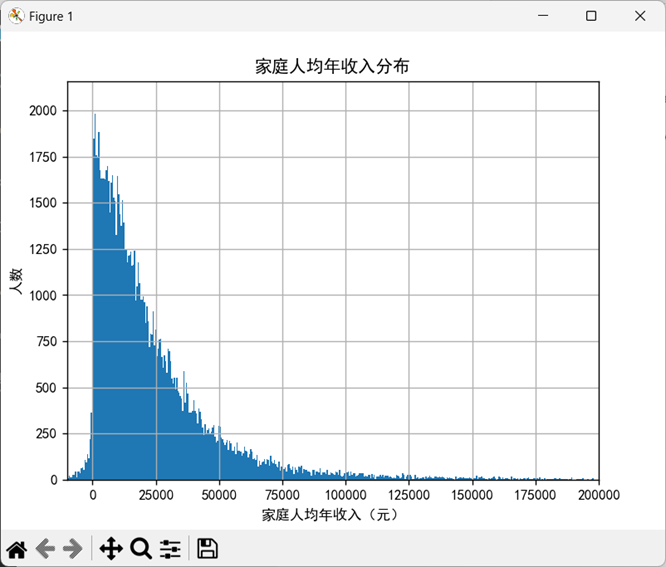
如图10-P3所示,绝大多数居民的家庭人均年收入在5万元以下,人均家庭年收入超过20万的居民凤毛麟角,这与各种社交媒体各博主自吹自擂的人均年入20万相去甚远。
IDLE Shell
1 | >>>r = avg >= 200000 #统计家庭人均年收入达到20万的样本数量 |
将avg与200000进行比较,可得一个包含多个布尔值的Series。进一步执行r.value_counts()可知,在106754个样本中,仅有961人的家庭人均年收入达到20万。
IDLE Shell
1 | >>>r.value_counts()[True] / r.shape[0] |
将r.value_counts()统计结果中为True的人数除以调查样本总数,可知家庭人均年收入达到20万的人群比例仅为千分之九。
IDLE Shell
1 | >>>r = (avg < 12000) #统计小于12000的样本数量 |
以类似的方法也可以统计家庭人均年收入不足1000元(对应年收入12000元)的人群占比。上述执行结果显示,该比例约为40.5%。读者可根据14亿人口加上上述比例估计贫困人口数量。(此处不便列出)
躬行实践
10-x (人均家庭财产) 请读者以上述统计结果文件Stat.csv为基础,绘制人均家庭财产分布的直方图,并统计统计样本中人均家庭财产的均值和中位数。
财富基尼系数看贫富分化
按照本书第5章介绍的基尼系数计算方法,我们以前述金融调查数据的人均资产为基础,计算了财富基尼系数,并绘制了计算示意图,完整程序如下:
1 | #assetgini.py |
相关计算方法的细节请读者回顾第5章。此处仅就第11行代码加以说明。np.trapz(ys,x=xs)用于积分计算洛伦兹曲线下方B区域的面积,其中,xs为自变量值序列,ys则为函数值序列。查询numpy文档可知,在trapz()函数内部,也是使用复合梯形规则进行面积积分的。

上述财富基尼系数的计算结果比较意外,不便展示,请读者自行计算。数据和程序在本文开始部分有下载链接。
以重庆大学计算机学院硕士研究生的毕业薪资为例,作者进行了不靠谱的小样本调查:随机问了几个刚毕业的学生。学生毕业后首年收入平均在25万以上,50万到100万也不鲜见。根据上述统计结果,只有千分之九的居民人均家庭年收入在20万以上。这些毕业生,不论男女,都是赚钱好手,他们5年赚的钱,可能就是其他人一生的总和。学计算机的男生、女生,值得拥有。
数据及源代码下载
http://codelearn.club/download/Family.zip




