
1个字节的存储空间,最多能表达256种不同的值。如果只表达英文字符及其标点符号,1个字节足够。但其它文字,比如中文,其“字符”有数万之多。在编码其它语言文字时,可能会使用到不同的多字节编码方案。
版权声明
本文可以在互联网上自由转载,但必须:注明出处(作者:海洋饼干叔叔)并包含指向本页面的链接。
本文不可以以纸质出版为目的进行改编、摘抄。
1. 文本编码与解码
计算机是二进制的,它的文件和内存严格地说,只能存储和处理比特流,每个比特对应二进制的1位。由于这些二进制位按8位一组被分隔成字节,我们也可以认为计算机只能存储和处理字节流,用大白话说就是一个接一个的字节。
所以,当我们把由多个字符构成的文章存储到计算机里的时候,存入到内存或者硬盘的并不是文字本身,而是这些文字字符的对应编码。我们以ASCII码为例为说明相关过程。ASCII码是所谓美国标准信息交换代码,它用一个字节来表示一个字符。一个字节有8位,共256种组合,用来表示英文字符、数字及标点绰绰有余。
ASCII码的完整码表请见: 美国信息交换标准交换代码表 - Python,C/C++ Club (codelearn.club)
为便于讨论,我们在Windows下用记事本编辑了如下内容的文件,并保存为hw.txt。
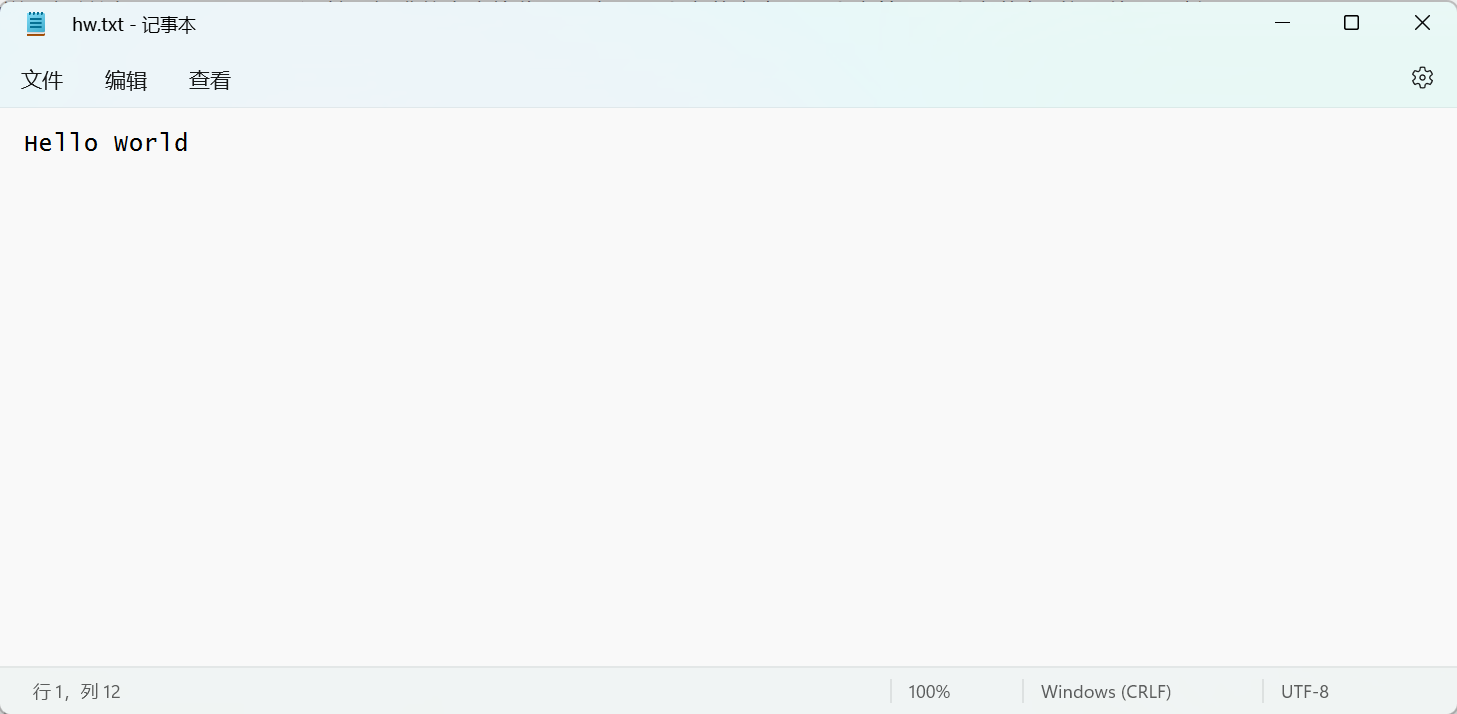
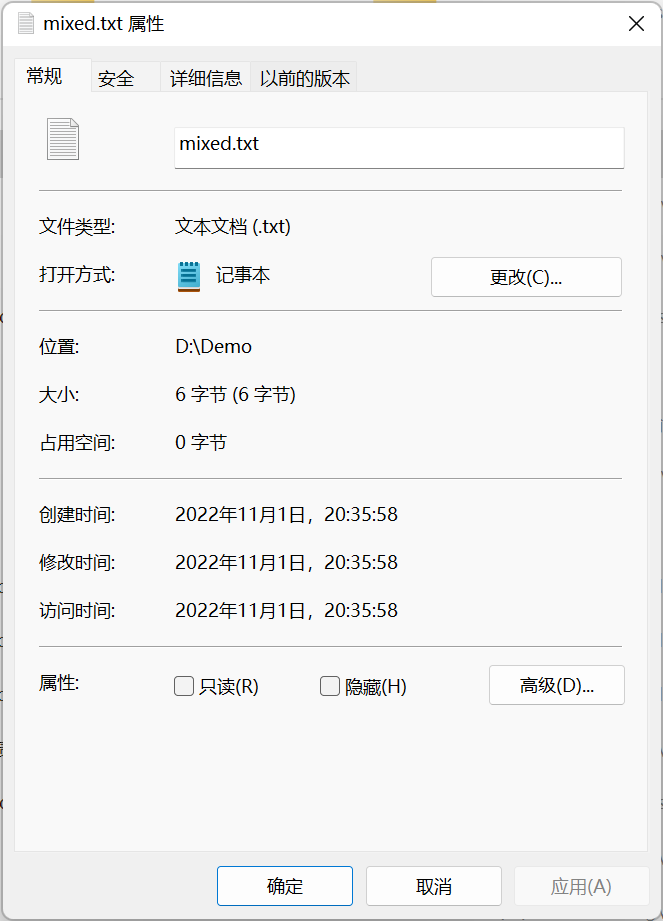
查看hw.txt的文件属性,可见该文件事实上占据了11个字节的空间。
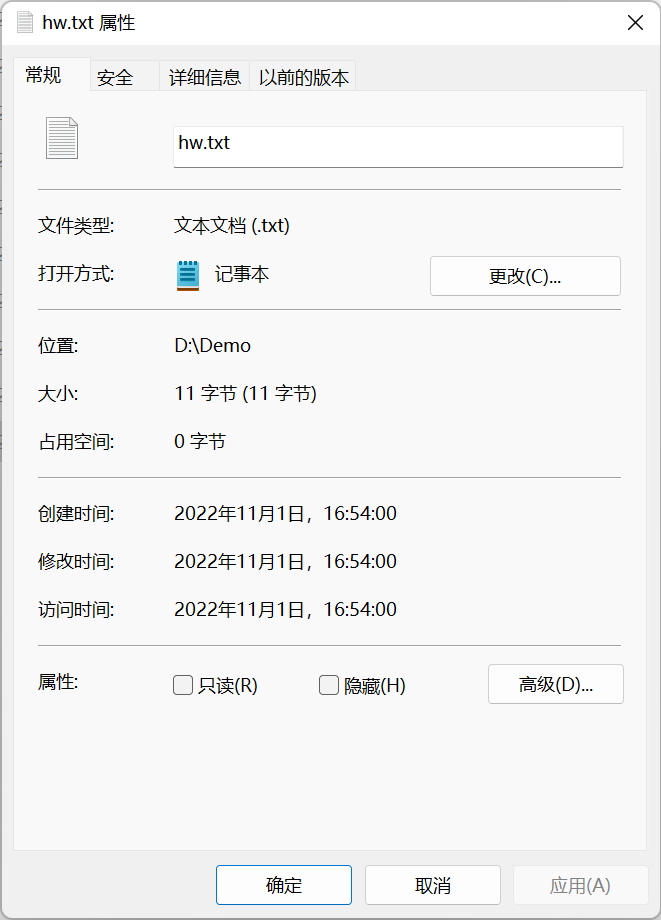
回顾hw.txt的文件内容,其中的”Hello World”连同其中的空格一起,正好11个字符。
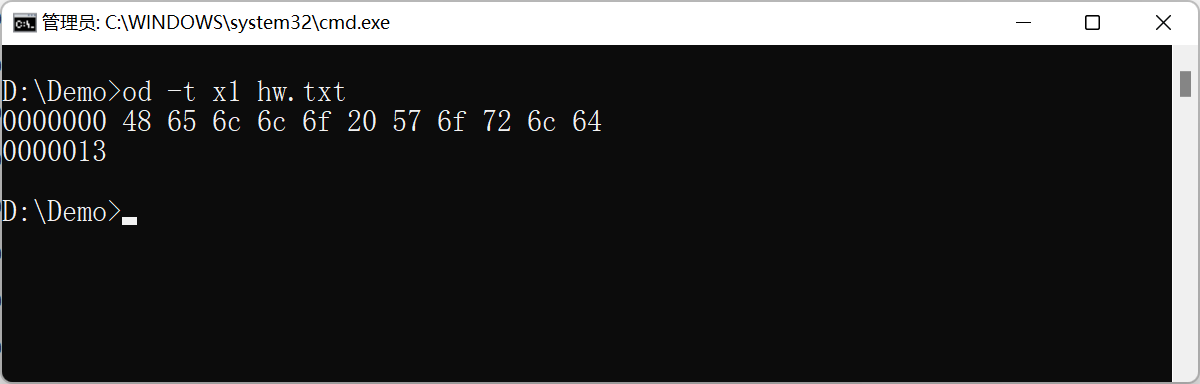
注意:000000 000013表示序号,不是文件的构成内容。
在Windows命令行下,使用如上图所述的od命令可以查看文件hw.txt的原始内容,其内的11个字节的值用16进制表示出来就是:
1 | 48 65 6C 6C 6F 20 57 6F 72 6C 64 |
其中,48在ASCII码里对应’H’,65对应’e’,20对应空格,64对应’d’…
文本编码
将文本存储至计算机内时,需要先把文本中的字符逐一转换成对应的编码,这一过程被称为”文本编码“。比如,文本”Hello World”被编码成字节流”48 65 6C 6C 6F 20 57 6F 72 6C 64“。
文本解码
对于Windows记事本而言,文件hw.txt就是包含11个字节的字节流,需要将这11个字节按照码表映射至文本,再显示出来,这一过程被称为”文本解码“。比如,字节流”48 65 6C 6C 6F 20 57 6F 72 6C 64“被转换成”Hello World”。
编码方案
同一文字符号,在不同的编码方案内,其对应的字节或字节序列很可能不同。
- ASCII码使用一个字节表示一个字符,而1个字节仅有8个比特,256种组合,因此,ASCII码只能表示英文字母、数字及符号。
- GB2312-80(汉语国标)使用双字节来表示一个汉字符号,同时,为了兼容英文,也用单字节来表示英文字符。理论上,GB2312-80可以较好地支持同一个文件内的中英文混合表达。但随着国际交流的日益频繁,在同一个网页或者文档里, 英、法、日、中、泰、韩等多国语言交替使用的场景屡见不鲜,此时,GB2312-80就不够用了。 后来国家又出手搞了GB18030… 但事实上未获得广泛应用。
为了促进世界大同,有人弄出了Unicode®,这种编码方案可以在同一文档/网页内容纳多国语言没有歧义地混合使用。
2. Unicode®
粗略地理解,Unicode就是一张表,这张表将世界上”所有“的文字字符,甚至一些表情符号(emoji表情)对应成互不相同的整数。Unicode®自发明以来,一直在不断修订中,以收录”新“的语言符号。至2022年9月13日止,Unicode® 15.0.0总共收录了149,186个字符。Unicode的表太长,下表给出了其中的几个示例。
| 符号 | 编码(整数,16进制) | 说明 |
|---|---|---|
| B | 0042 | 英文字符 |
| Ê | 00CA | |
| ڣ | 06A3 | 阿拉伯语字符 |
| ॵ | 0975 | 未知语言字符 |
| ᅰ | 1170 | 韩语符号 |
| ∫ | 222B | 数学符号之积分 |
| ⛺ | 26FA | 帐篷 |
| ざ | 3056 | 日语假名 |
| 人 | 4EBA | 汉字 |
3. UTF-8
UTF-8可以认为是Unicode的一种实施方案,通过UTF-8可以把一个字符对应的Unicode编码(一个整数)转换成一个字节序列,这个字节序列可能包含1个、2个、3个或者4个字节。
| Unicode编码(16进制) | UTF-8字节序列 | 说明 |
|---|---|---|
| 000000 ~ 00007F | 0xxxxxxx | 单字节, 含7个x |
| 000080 ~ 0007FF | 110xxxxx 10xxxxxx | 2字节,含11个x |
| 000800 ~ 00FFFF | 1110xxxx 10xxxxxx 10xxxxxx | 3字节, 含16个x |
| 010000 ~ 10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 4字节, 含21个x |
转换举例
对于英文字母、数字及英文符号,其Unicode编码与ASCII是一致的, 其值≤0x7F,按上表的规则,仍使用单字节编码。比如,’B’的Unicode编码为00004216,转换成7位二进制即为10000102,逐一替换上表第1行中的7个x,即为010000102,仍是4216,与’B’的ASCII码值完全相同。
对于阿拉伯母字符’ڣ’,其Unicode编码为06A316,其值满足上表第2行的条件,按规则应使用2字节编码。06A316转换成11位二进制即为110101000112,逐一替代上表第2行中的11个x,即为11011010 101000112,按16进制表达即为DA A316。
对于汉字’人’,其Unicode编码为4EBA16,其值符合上表第3行的条件,按规则应使用3字节编码。4EBA16转换成16位二进制即为01001110 101110102,逐一替代上表第3行中的16个x,即为11100100 10111010 101110102,按16进制表达即为E4 BA BA16。
3. UTF-8编码示例
我们使用Windows记事本编辑了一个”多国语言文件”,其中包含英文字母“B”,阿拉伯母字母“ڣ”,以及汉语的“人”,然后按UTF-8编码保存为文件mixed.txt。
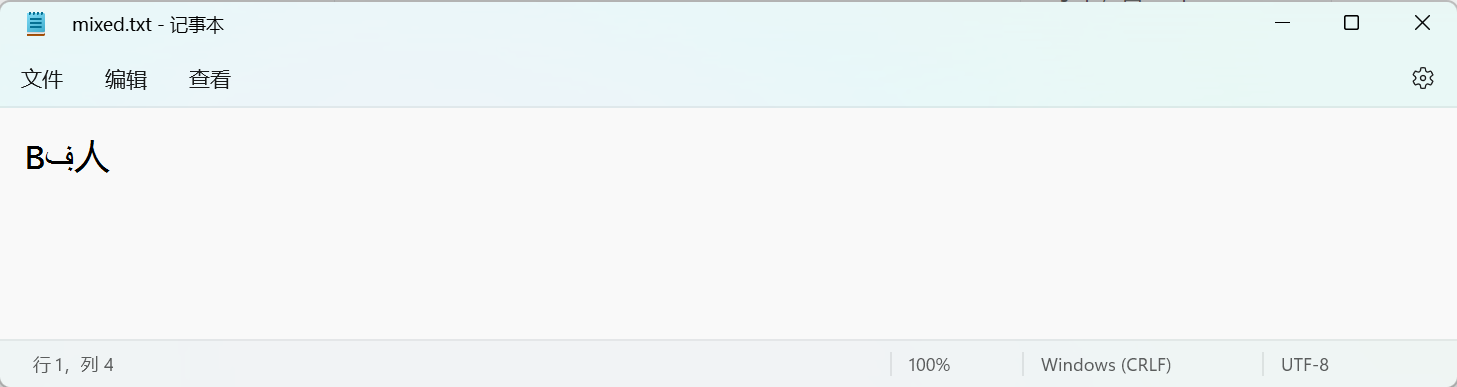
注意保存时选择UTF-8编码。
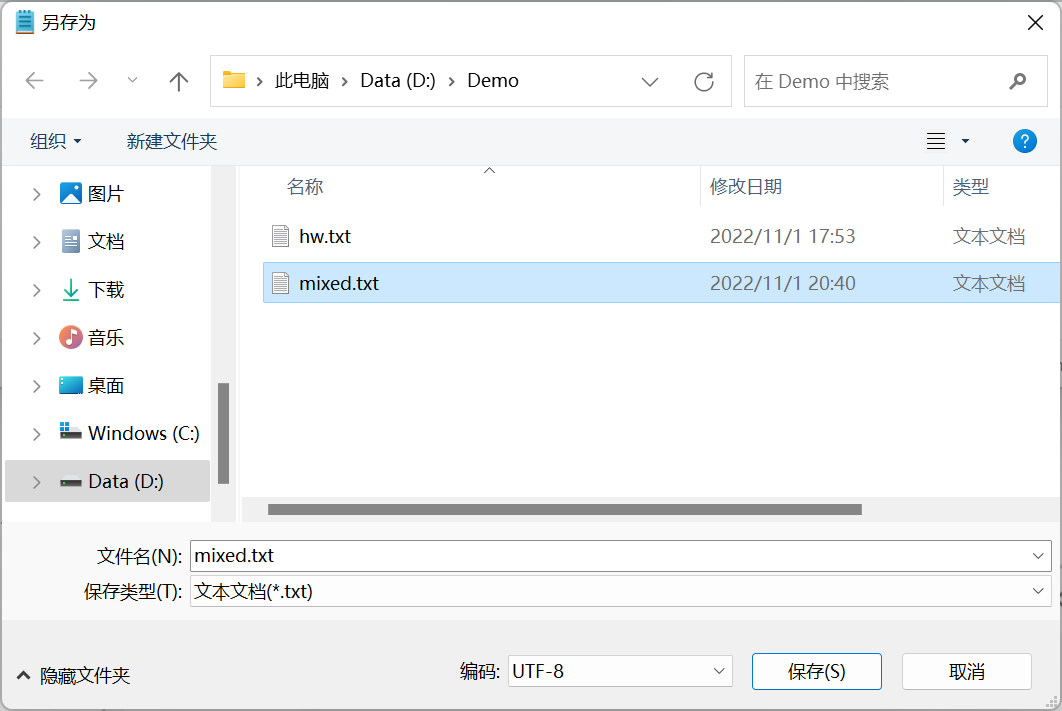
查看mixed.txt文件属性,发现其尺寸为6个字节。
再次使用od命令查看文件mixed.txt的原始内容,结果如下:

注意:000000, 000006是序号信息,不是文件的构成部分。
其中的”42 DA A3 E4 BA BA”与前述分析完全相同。编码程序完全按照上述UTF-8规则将文字”Bڣ人”转换为字节序列”42 DA A3 E4 BA BA”,然后把这个字节序列共6个字节写入文件mixed.txt。
4. UTF-8的模拟解码
当我们用记事本将文件mixed.txt中的原始内容读出时,其就是由6个字节构成的字节序列:42 DA A3 E4 BA BA16。 作为一个文字编辑软件,记事本需要通过UTF-8解码将上述字节序列查表转换成”Bڣ人”,然后再将其显示出来。字符的显示过程涉及绘图、字体等内容,此处略去不提。
我们可以假想出记事本软件内部的解码程序的执行过程:
- 解码程序从前至后逐一扫描字节序列,首先遇到4216,即010000102,该字节的最高位为0,根据表2,该字节为1字节编码,其单独表示一个Unicode字符,按表2第1行的规则从中取得后7个比特,其值仍为4216,查Unicode表,即得英文字符’B’。
- 解码程序继续扫描,得DA16,即110110102,其高3位为110,根据表2,该字节连同后面的A3合为一个2字节编码,按表2第2行的规则从中抽取11个比特,得110101000112,即06A316,查Unicode表,即得阿拉伯语字符‘ڣ’。
- 解码程序继续扫描,得E416,即111001002,其高4位为1110,根据表2,该字节连同后面的BA BA合为一个3字节编码,按表2第3行的规则从中抽取16个比特,得01001110 101110102,即4EBA16,查Unicode表,即得汉字’人’。
- 字节序列结束,解码程序终止。
从上述解码过程,读者不难看出,UTF-8的编码是没有歧义的,即特定的字节序列与特定的文本内容一一对应。在以汉字为主的文档里,使用UTF-8编码,一个汉字需要3个字节来表达,而使用GB2312-80,一个汉字只需要2个字节来表达。相较于后者,UTF-8编码的文档需要占据更多的存储空间以及网络带宽。
5. UTF-16, UTF-32
作者觉得没什么意思,UTF-8现在是主流,读者在安装Linux,设计网页时,如果选用UTF-8编码,是最安全的。
事实上,除了UTF-8,GB2312-80,ASCII,世界还有很多很多乱七八糟的编码方案…
6. 为什么会乱码

读者或许在程序开发的过程中看到过如上图所示的乱码现象。所谓乱码,本质是文本编码与文本解码发生了错位,如果把一个GB2312-80编码的文档按照UTF-8来进行解码,自然会发生错误,形成所谓“乱码”。
